
Effectiveness of Data Mining Algorithm in Predicting Post Lung Resection Surgery Prognosis

by Steve Iduye BN, MHI
and Xiaoqing Zhuang B.Sc. MHI,
Faculty of Computer Science, Dalhousie University,
Halifax Nova Scotia, Canada.
Abstract
Objective: In this paper, we examined the pre-surgery pathological variables that predict the chances of death or survival post-lung cancer resection surgery.
Methods: Data was pre-processed to eliminate missing data and outliers, which helped to arrange and analyze the most appropriate variables for the study. A classification rule – Decision Tree, Naïve Bayes, and Logistic Regression algorithm – was used in the WEKA data mining software with an interpretation of the results.
Results: Patients aged 43 years and below or 65 years and above were positively associated with the odds of dying post lung resection surgery. Large tumour size was a predictor of post lung surgery death in this population, while small tumour size in the age group 43-65 was associated with a better chance of survival. The presence of multiple pathological variables slightly increased the probability of death in the older adult population.
Conclusion: Lung resection surgery still poses a significant threat to patients’ odds of survival. Early diagnosis and tumour removal offer a better prognosis and an increased chance of survival.
Keywords: prognosis, lung resection, algorithm, classification rule, unsupervised learning.
Introduction
 Surgical resection is the foremost curative therapy for lung cancer (Reif, Socinski & Rivera, 2000). In an epidemiological report from the National Cancer Institute of Canada (1992), lung cancer was indicated as a common malignancy and a leading cause of death for both genders in Canada. The following factors are implicated for high survival rates in the patient population: female gender (Batevik, Grong, Segadal & Stangeland, (2005); Bernard, Ferrand, Hagry, Benoit, Cheynel & Favre (2000); Belani, Marts, Schiller, & Socinski (2007); Hung, Wang, Huang, Huang, Hsu & Wu (2007); Myrdal, Gustafsson, Lambe, Horte, & Stahle (2001); Visbal, Williams, Nichols, Marks, Jett, Aubry, Edell, Wampfler, Molina, & Yang, (2004). lower age group (Batevik, et al. (2005); Bernard, et al. (2000); Hung, et al. (2007); Myrdal, et al. (2001); Bernard, Deschamps, Allen, Miller, Trastek, Jenkins, & Pairolero (2001); Harpole, Decamp, Daley, Hur, Oprian, Henderson, & Khuri (1999). early pathological stage (Batevik, et al. (2005); Ploeg, Kappetein, van Tongeren, Pahlplatz, Kastelein, & Breslau, (2003); tumor removal from the lung (Batevik, et al. (2005); Myrdal, et al. (2001); Harpole, et al. (1999), Ploeg, et al. (2003); Cancer Registry of Norway, (n.d.); Volpino, Cangemi, Fiori, Cangemi, De Cesare, & Corsi, et al. (2007); no pre-coronary heart disease (Kearney, Lee, Reilly, Decamp, & Sugarbaker (1994); Stephan, Boucheseiche, Hollande, Flahault, Cheffi, Bazelly, & Bonnet (2000); Licker, de Perrot, Hohn, Tschopp, Robert, Frey, Schweizer, & Spiliopoulos (1999); and a normal pulmonary function test (Bernard, et al. (2000); Myrdal, et al. (2001); Bernard, et al. (2001); Kearney, et al. (1994); Bousamra, Presberg, Chammas, Tweddell, Winton, Bielefeld, & Haasler, (1996); Kroenke, Lawrence, Theroux, & Tuley (1992).
Surgical resection is the foremost curative therapy for lung cancer (Reif, Socinski & Rivera, 2000). In an epidemiological report from the National Cancer Institute of Canada (1992), lung cancer was indicated as a common malignancy and a leading cause of death for both genders in Canada. The following factors are implicated for high survival rates in the patient population: female gender (Batevik, Grong, Segadal & Stangeland, (2005); Bernard, Ferrand, Hagry, Benoit, Cheynel & Favre (2000); Belani, Marts, Schiller, & Socinski (2007); Hung, Wang, Huang, Huang, Hsu & Wu (2007); Myrdal, Gustafsson, Lambe, Horte, & Stahle (2001); Visbal, Williams, Nichols, Marks, Jett, Aubry, Edell, Wampfler, Molina, & Yang, (2004). lower age group (Batevik, et al. (2005); Bernard, et al. (2000); Hung, et al. (2007); Myrdal, et al. (2001); Bernard, Deschamps, Allen, Miller, Trastek, Jenkins, & Pairolero (2001); Harpole, Decamp, Daley, Hur, Oprian, Henderson, & Khuri (1999). early pathological stage (Batevik, et al. (2005); Ploeg, Kappetein, van Tongeren, Pahlplatz, Kastelein, & Breslau, (2003); tumor removal from the lung (Batevik, et al. (2005); Myrdal, et al. (2001); Harpole, et al. (1999), Ploeg, et al. (2003); Cancer Registry of Norway, (n.d.); Volpino, Cangemi, Fiori, Cangemi, De Cesare, & Corsi, et al. (2007); no pre-coronary heart disease (Kearney, Lee, Reilly, Decamp, & Sugarbaker (1994); Stephan, Boucheseiche, Hollande, Flahault, Cheffi, Bazelly, & Bonnet (2000); Licker, de Perrot, Hohn, Tschopp, Robert, Frey, Schweizer, & Spiliopoulos (1999); and a normal pulmonary function test (Bernard, et al. (2000); Myrdal, et al. (2001); Bernard, et al. (2001); Kearney, et al. (1994); Bousamra, Presberg, Chammas, Tweddell, Winton, Bielefeld, & Haasler, (1996); Kroenke, Lawrence, Theroux, & Tuley (1992).
On the other hand, recent medical literature has concluded that the prognosis of lung resection surgery generally depends on the patient’s clinical condition, gender and age, stage of the disease, tumor size, time of diagnosis, and histological type (Batevik, et al. (2005). Carcinoma of the lung remains a major health problem, with an overall five-year expectancy to live, and a survival rate of 9% for men and 12% for women, in Norway (Cancer Registry of Norway, (n.d.). This study examines the pre-surgery pathological variables that predict the chances of death or survival for post lung cancer resection surgery.
Data Discussion
The dataset for this study was collected by the Thoracic Surgery Centre (Poland) from patients who had undergone major lung resections for lung cancer between 2007-2011, with the data being stored in the UCI machine learning repository database and in the research database of the National Lung Cancer Registry, Poland.
In the dataset, patients were described by 16 variables, with 470 instances and participants and the variables could result in classes of either True or False (Live or Died). The information about what to expect was well communicated to the patients that participated in the data collection. The continuous data included patients’ forced vital capacity (the maximum volume their lungs exhaled) and the patient’s age pre-surgery. Binary classifications were also included like the presence of pain pre-surgery, hemoptysis pre-surgery, cough pre-surgery, smoking, and the presence of asthma. Categorical attributes included DGN and PRE6, and PRE14 was an ordinal item set. The classifications predict whether the patient survived or died one year post lung resection surgery.
Dataset Attributes
- DGN: Diagnosis from ICD-10 codes representing primary and secondary, and multiple tumors (DGN2, DGN3, DGN4, DGN5, DGN6, DGN8).
- PRE4: Forced Vital Capacity (FVC numeric).
- PRE5: Volume exhaled at the end of first second of forced expiration (FEV1 numeric).
- PRE6: Performance status – Zebroids scale (PRZ2, PRZ1, PRZ0).
- PRE7: Pain before surgery (T, F).
- PRE8: Hemoptysis before surgery (T, F).
- PRE9: Dyspnoea before surgery (T, F).
- PRE10: Cough before surgery (T, F).
- PRE11: Weakness pre-surgery (T, F).
- PRE14: Size of the original tumor, ranging from (OC11 smallest – OC14 largest).
- PRE17: Type 2 DM (T, F).
- PRE19: Myocardial Infarction for 6 months (T, F).
- PRE25: Peripheral Arterial Diseases PAD (T, F).
- PRE30: Smoking (T, F).
- PRE32: Asthma (T, F).
- AGE: Age at surgery (numeric).
- Risk1Y: One-year survival period – (T)rue value if died (T, F)
Data Pre-Processing
Data generated from the real-world scenario could be incomplete or inconsistent, or could contain some noisy data. The process of knowledge discovery could be especially difficult when the data is noisy or unreliable. Furthermore, the quality of the mined results will be affected by the quality of the data, as low-quality data would lead to low quality results (Kotsiantis, Kanellopoulos, & Pintelas, 2006).Therefore, the data must be pre-processed before it is mined. In this paper, data pre-processing was conducted by WEKA in five successive steps: renaming attributes, detecting and replacing missing values, removing attributes, detecting and removing outliers, and discretizing the data.
Renaming attributes
Most of the attribute names in the dataset are represented by three letters and one digit (e.g., PRE4), which is inconvenient for data processing. For example, if you cannot remember the meaning of the letters, you will need to retrieve the full attributes’ name from the attributes form. To avoid this inconvenience, the attribute names should be replaced with their real names. The filter (weka.filters.unsupervised.attribute.RenameAttribute) was used to rename the attributes.
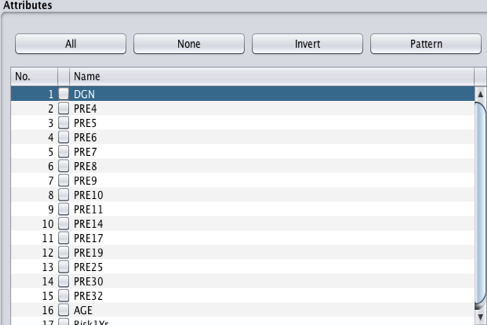
Figures 1: Original data set

Figure 2: shows what the replacements look like.
Detecting and replacing missing values
One of the important stages of the data pre-processing is dealing with missing data. By clicking on all the attributes in the attribute box, any missing data will be indicated by the missing value in the selected attribute box. When missing value is detected, the filter (weka.filters.unsupervised.attribute.ReplaceMissingValue) can be used to replace all missing values. That filter can replace the nominal missing value with the modes from the training data while replacing the numeric missing value with the means from the training data. Since no missing value was detected in the dataset, the step for replacing missing values could be skipped.
Removing attributes
In the thoracic surgery dataset, a total of 17 attributes are included. Nevertheless, not all of them were used in this project and some will be removed from the thoracic surgery dataset. The filter (weka.filters.unsupervised.attribute.Remove) was used to remove the unrelated attributes. The following attributes were also removed: Diagnosis, FVC, FEV1, Zscale, and Pain since they were not directly related to this study.
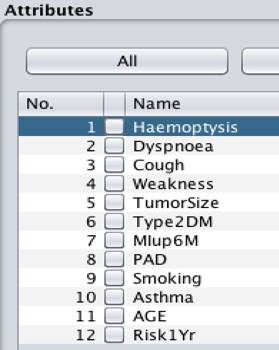
Figures 3 shows the attributes after some were removed.
Detecting and removing outliers
Outliers are observations that deviate far from the other observations, indicating that they may be bad or unnecessary confounding data. Outliers should be identified and deleted, using the filter (weka.filters.unsupervised.attribute.InterquartileRange) so that outliers, and extreme values can be detected. After applying the filter, two new attributes called “Outlier” and “ExtremeValue” were created in the attribute box (Figure 4). For some outliers to be removed from the dataset, the filter (weka.filters.unsupervised.attribute.RemoveWithValues) may also be used.
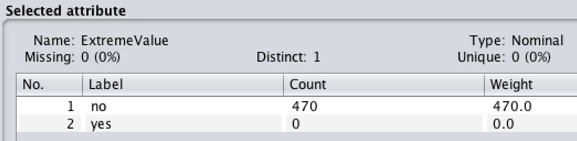
Figure 4 shows no outliers or extreme values
Discretization of data
In some techniques, such as the association rule, mining can only be performed with categorical data. The filter (weka.filters.unsupervised.attribute.Discretize) can be used to turn numeric or continuous values into nominal values. For this dataset, AGE is a numeric attribute, which should be discretized.
Figure 5: Age
Figure 6: Figures 5 and 6 show the process and results of discretization with the attribute AGE using 3 bins
Data Mining Methodology
Following the data preprocessing, clean datasets can be saved for the data mining processes. To find out if the attribute Age is significant for predicting the survival rate in post-operative lung resection (cardio-thoracic) surgery, a logistic regression algorithm was applied. The logistic regression algorithm method was used for the training set with a classifier filter (classifiers.function.Logistic) The logistic regression model also measured the relationship between the independent variables and the categorical variables by estimating probabilities using a logistic function. In the class attribute, an indicator (survive or die) was used, so the logistic regression model could be used to determine the relationship between that class attribute and attribute Age. The batch size equaling 100 was adequate for accurately estimating the gradient. Other optional values were set as default values.
For multiple risk factors like PAD, Tumor Size, Age, and MI predicting chances of survival, the preferred algorithm was a classification-based naïve Bayes method.
The decision tree induction method is a classification method that requires no domain knowledge and it is easy to use and understand. Moreover, the classification steps for the decision tree induction method are simple and fast and have a high accuracy. The decision tree algorithm used in WEKA (C4) was J48, which can generate a pruned or unpruned decision tree. This algorithm runs on the 70% training dataset and was tested on the 30% remaining data set.
Results and Interpretation
Logistic Regression
The performance accuracy of 86% and the recall performance classified the positive examples to 1.000. The odds ratio in the WEKA result shows whether an exposure is a risk factor for an outcome. If OR=1, exposure does not affect the odds of the outcome; if OR>1, the exposure is associated with a higher odd of the outcome; and if OR<1, the exposure is associated with a lower odd of the outcome [23]. Consequently, the OR of 1.9701 and 1.1459 for age groups less than or equal to 43 and greater than or equal to 65, respectively, the variable AGE is positively associated with the odds of dying post lung resection surgery. In the age group between 43 and 65 years; however, AGE is negatively associated with the chance of dying.
Figure 7 shows the odds ratio (OR) of post lung surgery.
Results of j48
The performance accuracy of the algorithm is 84% and the recall performance of 1.000 (Figure 8). Among patients less than or equal to 43 years of age or 65 years of age and older, large tumor sizes of 14 OC are predictive of post lung surgery death. Moreover, the smaller the tumor size (among patients in the 43-65 age group), the better the chance of surviving. The induction tree output also shows that a singular predictor (smaller tumor size), irrespective of age, does not increase the chance of dying post lung surgery.

Figure 8: Tumor sizes as predictors of post lung resection prognosis
Results of Naive Bayes
The performance accuracy of the algorithm was 84% and the recall performance was 1.000. Our Naïve Bayes algorithm (Figure 9) is based on the probability that the multiple pathological variables predict patient survival.
Figure 9: Multiple pathological variables as they predict prognosis
From the computations based on our Naïve Bayes algorithm and its notations, we obtained an overall probability of 0.15. This means that our multiple predictors have insignificant probability and does not predict survival in the population used for this study.
Discussion
This study showed that age (less than or equal to 43, greater than or equal to 65) and tumor size strongly influenced the chances of survival post lung resection, as multiple pathological variables predicting survival were insignificant. Thus, these age groups could benefit from lifestyle modification, early detection and screening, and other health promotion interventions pre- or post-operatively. Since the size of a tumor determined the chance of survival or death, patients should frequently undergo careful preoperative examinations and take every effort to elicit early removal of tumors. Although chronic disease management poses a great challenge to healthcare and to the patient population at large, we recommend that patients be proactive and emphasize preventive care, early diagnosis, and tumor removal to increase life expectancy. According to Aminian, Arbatani, Khajeheian, Zangi, & Shadmehr (2013) providing appropriate information to patients is a crucial part of any cancer program to achieve prevention, early diagnosis, and effective treatment processes. Measures need to be put into place by health policy-makers to improve the role of the media in raising public awareness, which is less expensive than relying on delayed or ineffective cancer treatments.
Limitations of the Study
Initially, the attribute names were troublesome in the dataset processing. The original attribute names only showed three letters with up to two digits (e.g., PRE4), which resulted in some mistakes when algorithms were implemented with the wrong attribute. Another difficulty occurred when implementing the j48 tree-based decision-making algorithm. With the clean dataset, j48 can help in building a pruned decision tree with high accuracy. Nevertheless, the result was only one size and one level of the decision tree which is too simple to provide precise information. Therefore, using the j48 pruning function is not necessary for this dataset. Finally, the dataset overall was too small to generalize our conclusion.
Conclusion
This study provided insight into life expectancy post lung cancer resection. Our chosen algorithms were reasonably accurate in most of the cases. Some of the shortcomings were likely due to the relatively small dataset, which reduced the performance of some of the algorithms. The results suggest that for the less than or equal to 43-year age group and the greater than or equal to 65 age group, tumor growth (i.e., size) is a fair predictor of death post lung resection surgery. Multiple pathological variables showed no significance in predicting survival in the study population. Further research in this area is needed to ascertain which other variables might be influencing death or survival post lung resection surgery, especially with the prevalence of disease comorbidity for the patient population. Lifestyle modification and health promotion programs before the onset of the disease process would also be crucial for managing cases of lung cancer. Along this line, the media could play a significant role to encourage the population to embrace lifestyle modifications and adopt better health practices.
References
Bousamra, M., Presberg, K.W., Chammas, J.H., Tweddell, J.S., Winton, B.L., Bielefeld, M.R, et al. (1996). Early and late morbidity in patients undergoing pulmonary resection with low diffusion capacity. Annals of Thoracic Surgery, 62:968-974.
Bernard, A., Ferrand, L., Hagry, O., Benoit, L., Cheynel, N., Favre, J.P. (2000). Identification of prognostic factors determining risk groups for lung resection. Annals of Thoracic Surgery, 70:1161-1167.
Bernard, A., Deschamps, C., Allen, M.S., Miller, D.L., Trastek, V.F., Jenkins, G.D, et al. (2001). Pneumonectomy for malignant disease: Factors affecting early morbidity and mortality. Journal of Thoracic and Cardiovascular Surgery, 121:1076-1081.
Bach, P.B., Cramer, L.D., Schrag, D., Downey, R.J., Gelfand, S.E., Begg, C.B. (2001) The influence of hospital volume on survival after resection for lung cancer. New England Journal of Medicine, 345:181-188.
Bernard, A., Deschamps, C., Allen, M.S., Miller, D.L., Trastek, V.F., Jenkins, G.D, et al. (2001). Pneumonectomy for malignant disease: Factors affecting early morbidity and mortality. Journal of Thoracic and Cardiovascular Surgery, 121:1076-1081.
Batevik, R., Grong, K., Segadal, L., Stangeland, L. (2005). The female gender has a positive effect on survival independent of background life expectancy following surgical resection of primary non-small cell lung cancer: A study of absolute and relative survival over 15 years. Lung Cancer, 47(2),173-181.
Belani, C.P., Marts, S., Schiller, J., Socinski, M.A. (2007). Women and lung cancer: Epidemiology, tumour biology, and emerging trends in clinical research. Lung Cancer, 55:15-23.
Cancer Registry of Norway. (2006). Lung Resection. Retrieved from http://www.kreftregisteret.no
Gail, M.H., Eagan, R.T., Feld, R., Ginsberg, R., Goodell, B., Hill, L., et al. (1984). Prognostic factors in patients with resected stage I non-small-cell lung-cancer – A report from the Lung-Cancer Study Group. Cancer, 54:1802-1813.
Harpole, D.H., Decamp, M.M., Daley, J., Hur, K., Oprian, C.A, Henderson, W.G, et al. (1999). Prognostic models of thirty-day mortality and morbidity after major pulmonary resection. Journal of Thoracic and Cardiovascular Surgery, 117:969-979.
Hung, J.J., Wang, C.Y., Huang, M.H., Huang, B.S., Hsu, W.H., Wu, Y.C. (2007). Prognostic factors in resected stage I non-small-cell lung cancer with a diameter of 3 cm or less: Visceral pleural invasion did not influence overall and disease-free survival. Journal of Thoracic and Cardiovascular Surgery, 134:638-643.
Kearney, D.J., Lee, T.H., Reilly, J.J., Decamp, M.M., Sugarbaker, D.J. (1994). Assessment of operative Risk in patients undergoing lung resection – Importance of predicted pulmonary-function. Chest, 105:753-759.
Kroenke, K., Lawrence, V.A., Theroux, J.F., Tuley, M.R. (1992). Operative risk in patients with severe obstructive pulmonary disease. Archives of Internal Medicine, 152:967-971.
Kotsiantis, S.B., Kanellopoulos, D., Pintelas, P.E. (2006). Data preprocessing for supervised learning. International Journal of Computer Science, 1(1),1306-4428.
Licker, M., de Perrot, M., Hohn, L., Tschopp, J.M., Robert, J., Frey, J.G, et al. (1999). Perioperative mortality and major cardio-pulmonary complications after lung surgery for non-small cell carcinoma. European Journal of Cardio-Thoracic Surgery, 15:314-319.
Lubicz, M., Pawelczyk, K., Rzechonek, A., Kolodziej, j. (2013). Thoracic Surgery Data Set. http://archive.ics.uci.edu/ml/datasets/Thoracic+Surgery+Data#
Myrdal, G., Gustafsson, G., Lambe, M., Horte, L.G., Stahle, E. (2001). Outcome after lung cancer surgery. Factors predicting early mortality and major morbidity. European Journal of Cardio-Thoracic Surgery, 20:694-699.
National Cancer Institute of Canada. (1992). Canadian Cancer Statistics. Toronto.
Ploeg, A.J., Kappetein, A.P., van Tongeren, R.B., Pahlplatz, P.V., Kastelein, G.W., Breslau, P.J. (2003). Factors associated with perioperative complications and long-term results after pulmonary resection for primary carcinoma of the lung. European Journal of Cardio-Thoracic Surgery, 23:26-29.
Reif, M.S., Socinski, M.A., Rivera, M.P. (2000). Evidence-based medicine in the treatment of non-small cell lung cancer. Clinics in Chest Medicine, 21:107-120.
Stephan, F., Boucheseiche, S., Hollande, J., Flahault, A., Cheffi, A., Bazelly, B., et al. (2000). Pulmonary complications following lung resection – A comprehensive analysis of incidence and possible risk factors. Chest, 118:1263-1270.
Szumilas, M. (2010). Explaining odds ratios. Journal of the Canadian Academy of Child and Adolescent Psychiatry, 19(3), 227-229.
Visbal, A.L., Williams, B.A., Nichols, F.C., Marks, R.S., Jett, J.R., Aubry, M.C, et al. (2004). Gender differences in non-small-cell lung cancer survival: An analysis of 4,618 patients diagnosed between 1997 and 2002. Annals of Thoracic Surgery, 78 :209-215.
Volpino, P., Cangemi, R., Fiori, E., Cangemi, B., De Cesare, A., Corsi N, et al. (2007). Risk of mortality from cardiovascular and respiratory causes in patients with chronic obstructive pulmonary disease submitted to follow-up after lung resection for non-small cell lung cancer. Journal of Cardiovascular Surgery, 48:375-383.
Zhang, J., Gold, K. A., Lin, H. Y., Swisher, S. G., Xing, Y., Lee, J. J., Kim, E. S., & William, W. N., Jr (2015). Relationship between tumour size and survival in non-small-cell lung cancer (NSCLC): an analysis of the surveillance, epidemiology, and end results (SEER) registry. Journal of Thoracic Oncology, 10(4), 682–690. https://doi.org/10.1097/JTO.0000000000000456
Conflicts of Interest
None
Correspondence
Steve Iduye BN, MHI
Faculty of Computer Science, Dalhousie University
Halifax, Nova Scotia, Canada
Email: Steve.Iduye@dal.ca
Phone: 1902-305-4827
Xiaoqing Zhuang B.Sc. MHI
Service Nova Scotia, Government of Nova Scotia
Halifax Nova Scotia, Canada
Email: x2012att@gmail.com.
Phone: 1902-2207-892
OUR SPONSORS

Visit the Nursing Informatics Learning Center for resources, courses, news, and other informatics related content.




Recent articles
- Index of Volume 18 Number 322 Sep 2023
- Trends in Remote Patient Monitoring22 Sep 2023
- Evaluation of Smart Pill Bottle Systems on Medication Compliance: An Integrative Review22 Sep 2023
- Usability of the PulsePoint app in improving community response efforts22 Sep 2023
- A Systematic Review on Nursing Students’ Experiences with eLearning22 Sep 2023